This article builds on a previous post: how to capture clickstream events in Kafka with Snowplow, where we capture clickstream events in Kafka (specifically Confluent Cloud).
In this post we’ll build a near real-time, Neo4j-based recommendation engine from the clickstream of page views.
Snowplow tag and recommender data flow
When a reader of this blog opens a page, the Snowplow tag executes. If a cookie doesn’t already exist, the tag creates one that lasts for 365 days. The cookie contains a domain_userid which can be retrieved by calling the getSnowplowDuid() function. Here’s an example, executed in Chrome’s console:
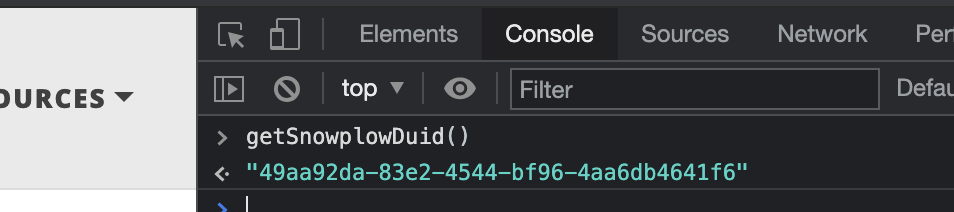
The Snowplow domain_userid is the identifier we’ll use to build the graph via the clickstream, and retrieve recommendations from the Neo4j-based recommender service.
A Javascript function, getRecommendations(), in recommendations.js runs in the browser, calls the recommender service, and displays the results on the page.
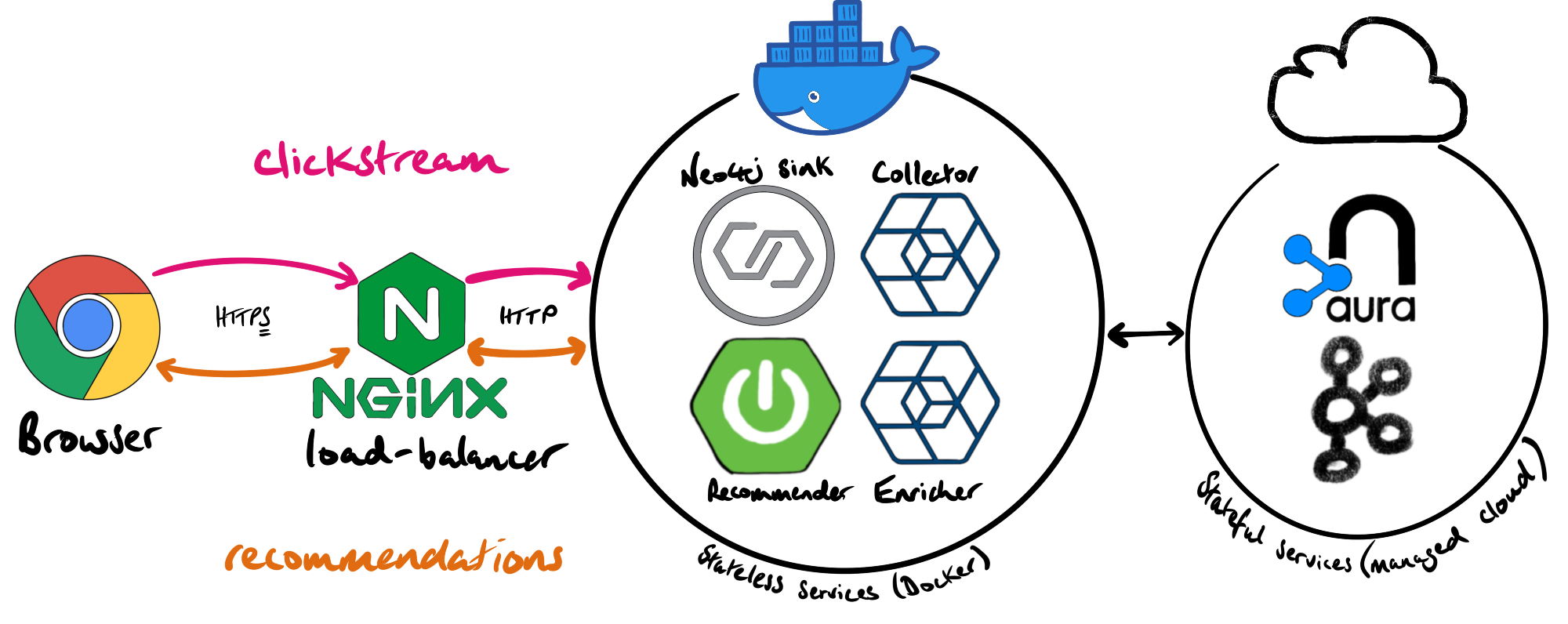
To reduce the risk of data loss, cost, and the level of effort to implement, we decided to use managed services (specifically Neo4j Aura and Confluent Cloud) for the stateful components. The stateless components were run in Docker containers.
build the graph in real-time with the Neo4j sink connector
The first step was to sink the clickstream events from Kafka into Neo4j. We created a Dockerized Kafka Connect instance with the Neo4j connector installed. The steps to create the custom Docker image with the Neo4j connector was documented in a previous blog post.
We created unique constraints to ensure that there can only ever be a single Page node for each page_url and, similarly, there can only be a single User node for each domain_userid:
CREATE CONSTRAINT page_page_url_unique IF NOT EXISTS ON (p:Page) ASSERT p.page_url IS UNIQUE;
CREATE CONSTRAINT user_domain_userid_unique IF NOT EXISTS ON (u:User) ASSERT u.domain_userid IS UNIQUE;
Adding these constraints also created indexes on these fields, which speeds up writes:
neo4j@neo4j> call db.indexes;
+--------------------------------------------------------------------------------------------------------------------------------------------------------------+
| id | name | state | populationPercent | uniqueness | type | entityType | labelsOrTypes | properties | provider |
+--------------------------------------------------------------------------------------------------------------------------------------------------------------+
| 1 | "page_page_url_unique" | "ONLINE" | 100.0 | "UNIQUE" | "BTREE" | "NODE" | ["Page"] | ["page_url"] | "native-btree-1.0" |
| 3 | "user_domain_userid_unique" | "ONLINE" | 100.0 | "UNIQUE" | "BTREE" | "NODE" | ["User"] | ["domain_userid"] | "native-btree-1.0" |
+--------------------------------------------------------------------------------------------------------------------------------------------------------------+
Without indexes, the writes would get exponentially slower with the size of the graph.
Here’s the PUT call, submitted via HTTPie to the Dockerized Kafka Connect instance, to deploy the Neo4j sink connector:
http PUT snowplow.woolford.io:8083/connectors/snowplow-neo4j/config <<< '
{
"connector.class": "streams.kafka.connect.sink.Neo4jSinkConnector",
"key.converter": "org.apache.kafka.connect.storage.StringConverter",
"name": "snowplow-neo4j",
"neo4j.server.uri": "neo4j+s://45940f18.databases.neo4j.io:7687",
"neo4j.authentication.basic.username": "neo4j",
"neo4j.authentication.basic.password": "********",
"neo4j.topic.cypher.snowplow-enriched-good-json": "MERGE(u:User {domain_userid: event.domain_userid}) MERGE(p:Page {page_url: event.page_url}) SET p.page_title: event.page_title MERGE(u)-[:VIEWED {timestamp: apoc.date.fromISO8601(event.derived_tstamp)}]->(p)",
"topics": "snowplow-enriched-good-json",
"value.converter": "org.apache.kafka.connect.json.JsonConverter",
"value.converter.schemas.enable": "false"
}'
Let’s take a closer look at the Cypher statement that’s executed for each event:
MERGE(u:User {domain_userid: event.domain_userid})
MERGE(p:Page {page_url: event.page_url})
SET p.page_title = event.page_title
MERGE(u)-[:VIEWED {timestamp: apoc.date.fromISO8601(event.derived_tstamp)}]->(p)
The MERGE is effectively an upsert. If an object (i.e. node or relationship) with the specific properties inside the MERGE doesn’t already exist, that object is created.
For the User nodes, we’re only storing a single property: the domain_userid. For the Page nodes, the page_url is the key, and the page_title is an additional property that could change. The recommender needs both the URL and title in order to create links on the page. We MERGE on the unique constraint key (e.g page_url) and SET any other properties associated with that key (e.g. the page_title).
In the first line, we create a User with the domain_userid property, and assign it to the alias u. Similarly, we do the same thing with the Page, based on the page_url property, which we assign to the alias p. We then create a :VIEWED relationship between the user (u) and the page (p), and add the timestamp property to that relationship.
Since the clickstream and recommendation engine are both brand new, the timestamp doesn’t provide a lot of informational value at the time of writing. We decided to capture it in the graph because we will eventually use the timestamp to boost the relevance of more recent activity and discount page views that happened a long time ago.
flag the pages containing articles
Not all the pages this blog are articles: there’s the homepage and tag index pages. We don’t want to include these in the recommendation results. Neo4j’s data model is extremely flexible, and it’s easy to write small utilities to add data elements to the graph. Here’s a simple Python example that adds an is_post=true property to each of the article pages:
#!/usr/bin/env python
import os
from neo4j import GraphDatabase
def set_neo4j_post_flag():
NEO4J_URI = os.getenv('NEO4J_URI')
NEO4J_USER = os.getenv('NEO4J_USER')
NEO4J_PASSWORD = os.getenv('NEO4J_PASSWORD')
driver = GraphDatabase.driver(NEO4J_URI, auth=(NEO4J_USER, NEO4J_PASSWORD), database="neo4j")
posts_files = os.listdir("_posts/")
for posts_file in posts_files:
post_file_no_extension=os.path.splitext(posts_file)[0]
page_url = "https://woolford.io/{post_file_no_extension}/".format(post_file_no_extension=post_file_no_extension)
with driver.session() as session:
session.run("MATCH(p:Page {page_url: $page_url }) SET p.is_post = true", page_url=page_url)
if __name__ == "__main__":
set_neo4j_post_flag()
This property will be used to ensure that only articles are returned as recommendations.
In addition to Python, there are supported client libraries for .Net, Java, Javascript and Go.
“If you liked this, you might also like that…”
The snowplow-neo4j-recommender service is a Spring Boot REST service that executes Cypher statements against a Neo4j database. Here’s an example API call to get recommendations for domain_userid ea1a9c2f-062e-4c15-9b42-36e9358f1462:
http https://snowplow.woolford.io:7443/recommendations/ea1a9c2f-062e-4c15-9b42-36e9358f1462
[
{
"id": 4,
"pageTitle": "Zeek, Kafka, and Neo4j",
"pageUrl": "https://woolford.io/2019-12-11-zeek-neo4j/"
},
{
"id": 1,
"pageTitle": "streaming joins in ksqlDB",
"pageUrl": "https://woolford.io/2020-07-11-streaming-joins/"
},
{
"id": 5,
"pageTitle": "a $10 pot of honey",
"pageUrl": "https://woolford.io/2018-02-11-cowrie/"
}
]
This service was embedded in a Docker container and pushed to DockerHub so it’s easy to deploy:
docker run -d -p 8081:8081/tcp --env-file snowplow-neo4j.env alexwoolford/snowplow-neo4j-recommender:1.0.0
snowplow-neo4j.env
SPRING_NEO4J_URI=neo4j+s://45940f18.databases.neo4j.io:7687
SPRING_NEO4J_AUTHENTICATION_USERNAME=neo4j
SPRING_NEO4J_AUTHENTICATION_PASSWORD=********
SPRING_DATA_NEO4J_DATABASE=neo4j
Now let’s walk through the recommender logic. Suppose we have a user a who viewed page x. And the other users who viewed page x also viewed pages y and z. All three of the other users viewed page y, and two out of three viewed page z. Our page recommendations are ranked by popularity amongst these common users. Our first recommendation for user a would be page y and our second recommendation would be page z:
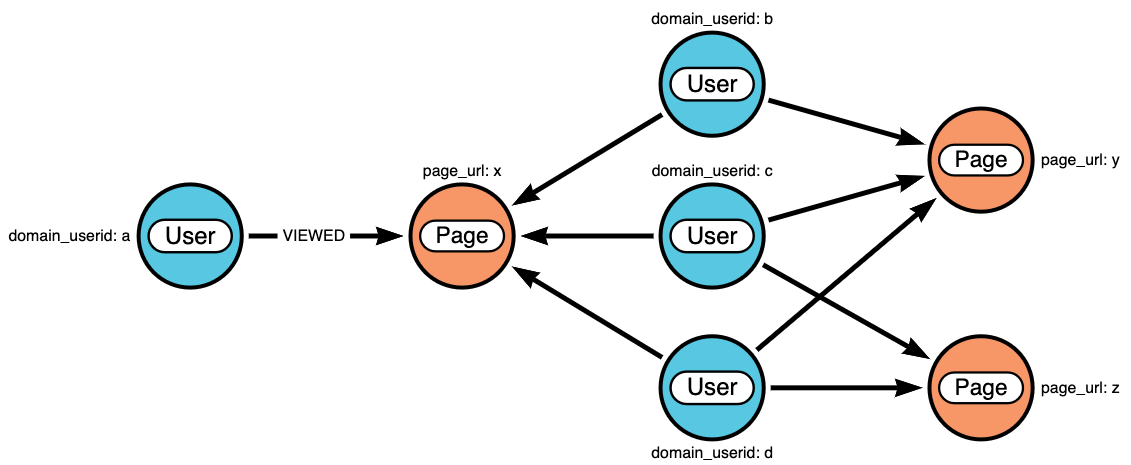
This logic was translated into a Cypher query that’s executed by the recommender REST service:
MATCH (user:User {domain_userid: 'ea1a9c2f-062e-4c15-9b42-36e9358f1462'})-[:VIEWED]->(page:Page)<-[:VIEWED]-(other_user:User)-[:VIEWED]->(other_page:Page)
WHERE user <> other_user
AND other_page.is_post = true
WITH other_page, COUNT(other_user) AS frequency
ORDER BY frequency DESC
RETURN other_page
LIMIT 3
The ORDER BY clause ranks the recommendations in descending order. The best recommendation is listed first. The LIMIT clause return just the top 3 results.
next
Now that we have a basic recommender service in place, we can begin the iterative process of making it better. We will explore chains of events (i.e. the :NEXT relationship), boosting, community detection, and AB-testing in a follow-up post.
Thanks for reading this post and becoming a node in our graph.