why handle events in real-time?
Snowplow allows us to capture user behavior, via a Javascript tag, at the individual level. In contrast to the most popular web analytics platform (Google Analytics) Snowplow captures personally identifiable data: IP addresses, cookies, etc. This individual-level data is more granular and actionable than anonymized aggregate data from Google Analytics.
The typical Snowplow architecture aggregates events into batches, loads them into a data warehouse, and the data analysis is post-hoc. As the events flow from the browser to the data warehouse, they’re persisted to a message queue: Apache Kafka.
{kind=link}
The value of data has a half-life. When a user views a page, the metadata of that page tells us what they’re interested in at that moment in time. Interests are often fleeting. If we don’t act right away, we’re leaving money on the table. We don’t need to wait in order to act.
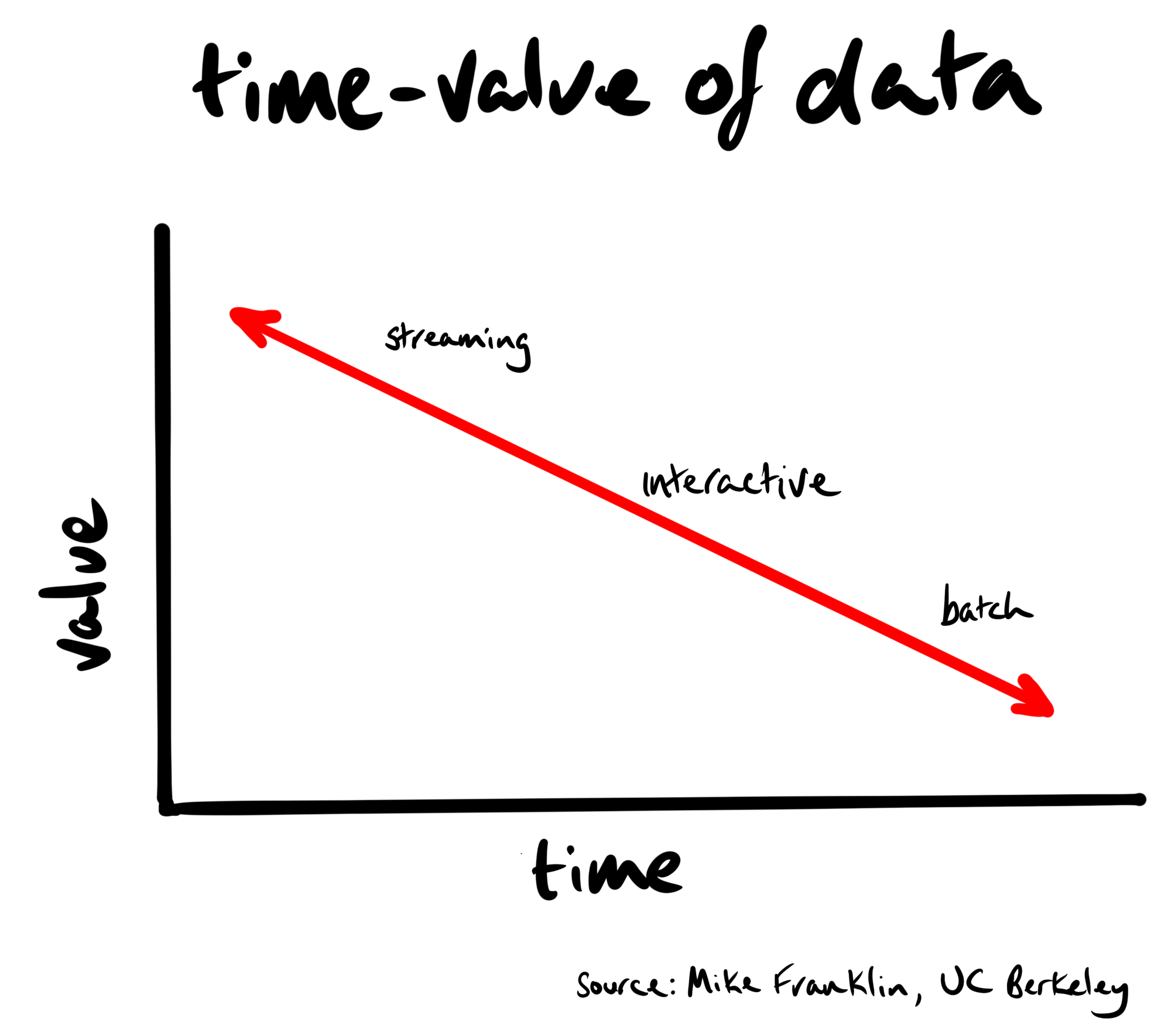
In this post, we’ll walk you through the steps to setup a near real-time event stream of JSON formatted events from a website to Apache Kafka (specifically, Confluent Cloud).
the Snowplow Javascript tag
The beginning of the chain starts with a Javascript tag. This executes in the browser when a user opens a page. For this event-feed, we’ll be using the Snowplow tag.
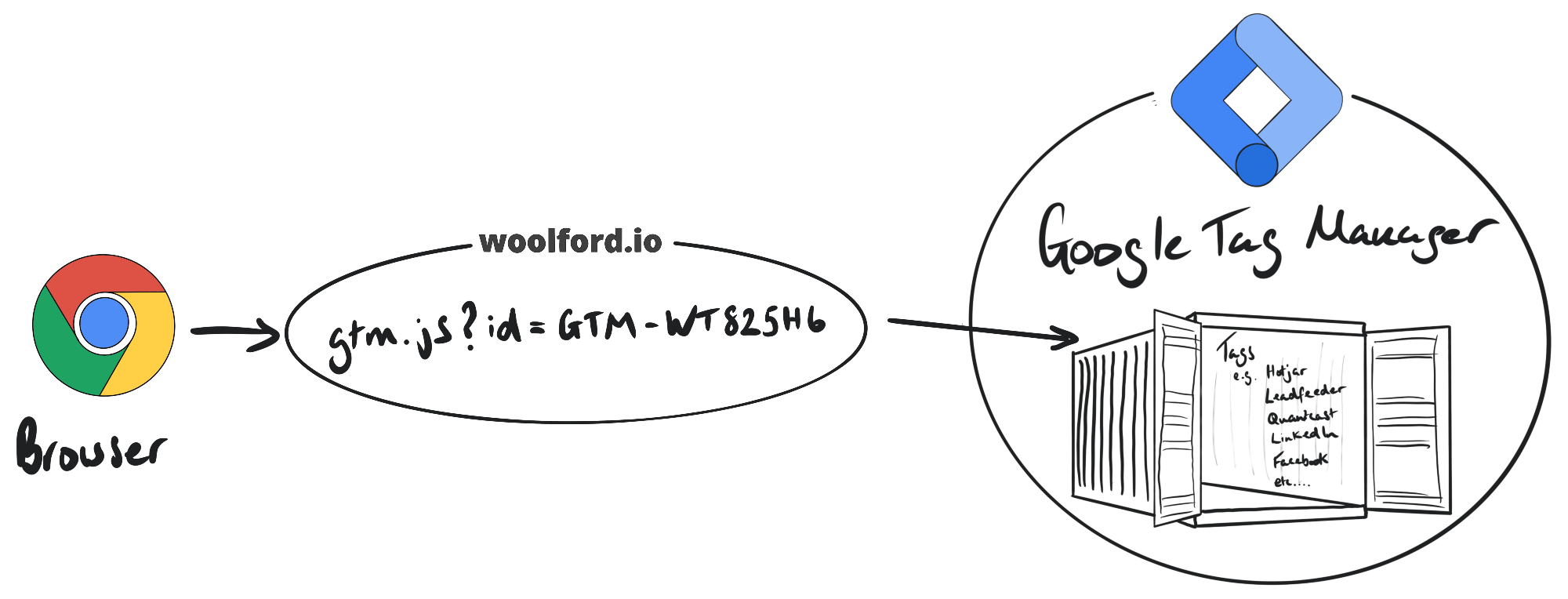
There are hundreds of services, many of which are free (or, more precisely, “freemium”), which entail installing tags on your site. Tag manager technologies such as Google Tag Manager, Tealium, and Segment allow users to manage the deployment of Javascript tags on the site. We added Google Tag Manager to our site, and used that to deploy the Snowplow Javascript tag.
Google Tag Manager places a container tag on the site which has all the other Javascript services inside it:
The Snowplow tag makes an HTTP call to the Snowplow Collector service, which is a Scala application running in a Docker container behind an Nginx load balancer. Secure sites (i.e. https) rank higher in search than insecure sites (i.e. http). While it is possible to add the appropriate certificates to the Scala Snowplow collector, it’s much easier terminate the SSL at the Nginx load-balancer thanks to the Let’s Encrypt’s certbot and its Nginx plugin.
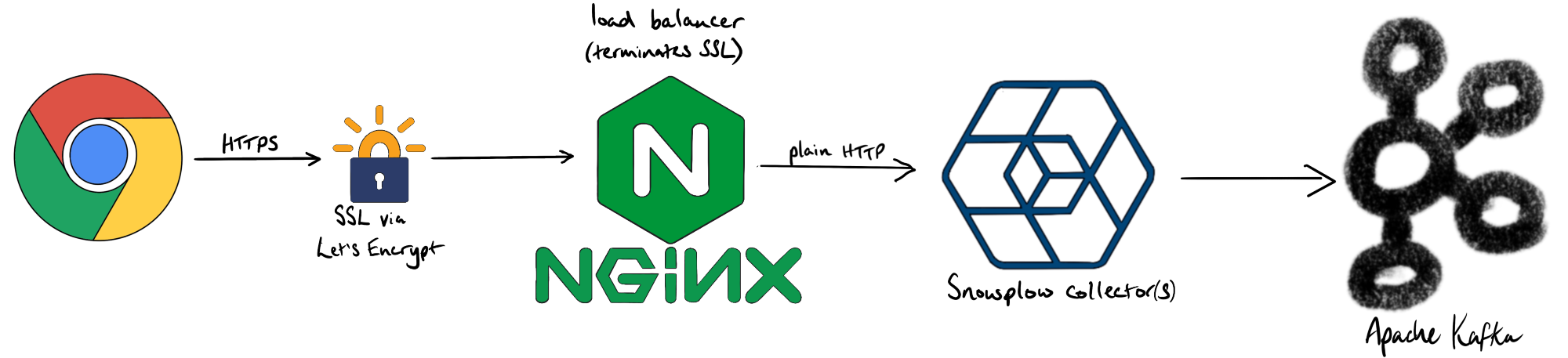
Here’s a snippet from our nginx.conf file:
server {
listen 8443 ssl;
listen [::]:8443 ssl ipv6only=on;
ssl_certificate /etc/letsencrypt/live/snowplow.woolford.io/fullchain.pem;
ssl_certificate_key /etc/letsencrypt/live/snowplow.woolford.io/privkey.pem;
include /etc/letsencrypt/options-ssl-nginx.conf;
ssl_dhparam /etc/letsencrypt/ssl-dhparams.pem;
server_name snowplow.woolford.io;
location / {
proxy_pass http://10.0.2.11:8080;
resolver 10.0.1.1;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
}
}
the Snowplow Collector
The Snowplow Collector was launched by running the snowplow/scala-stream-collector-kafka Docker container:
docker run -d -v \
$PWD/snowplow-config:/snowplow/config \
-p 8080:8080 \
snowplow/scala-stream-collector-kafka:2.3.0 \
--config /snowplow/config/collector.hocon
collector.hocon
collector {
interface = "0.0.0.0"
port = 8080
paths {
}
p3p {
policyRef = "/w3c/p3p.xml"
CP = "NOI DSP COR NID PSA OUR IND COM NAV STA"
}
crossDomain {
enabled = false
domains = [ "*" ]
secure = false
}
cookie {
enabled = true
expiration = "365 days"
# Network cookie name
name = "sp"
domains = [
"woolford.io"
]
secure = false
httpOnly = true
sameSite = "None"
}
doNotTrackCookie {
enabled = false
name = "opt-out"
value = ""
}
cookieBounce {
enabled = false
name = "n3pc"
fallbackNetworkUserId = "00000000-0000-4000-A000-000000000000"
forwardedProtocolHeader = "X-Forwarded-Proto"
}
enableDefaultRedirect = false
redirectMacro {
enabled = false
}
rootResponse {
enabled = false
statusCode = 302
}
cors {
accessControlMaxAge = 5 seconds
}
prometheusMetrics {
enabled = false
}
streams {
good = snowplow-good
bad = snowplow-bad
useIpAddressAsPartitionKey = true
sink {
enabled = kafka
brokers = "pkc-lzvrd.us-west4.gcp.confluent.cloud:9092"
retries = 0
producerConf {
acks = all
"security.protocol" = "SASL_SSL"
"sasl.jaas.config" = "org.apache.kafka.common.security.plain.PlainLoginModule required username='FQJBR6FKE5PQCAKH' password='********';"
"sasl.mechanism" = "PLAIN"
"client.dns.lookup" = "use_all_dns_ips"
}
}
buffer {
byteLimit = 16384
recordLimit = 5
timeLimit = 1000
}
}
}
akka {
loglevel = DEBUG
loggers = ["akka.event.slf4j.Slf4jLogger"]
http.server {
remote-address-header = on
raw-request-uri-header = on
parsing {
max-uri-length = 32768
uri-parsing-mode = relaxed
}
}
}
the Snowplow Enricher
Snowplow has an ecosystem of enrichments. The enricher was launched in a Docker container:
docker run -d -v \
$PWD/snowplow-config:/snowplow/config \
snowplow/stream-enrich-kafka:2.0.1 \
--config /snowplow/config/enrich.hocon \
--resolver file:/snowplow/config/iglu_resolver.json \
--enrichments file:/snowplow/config/enrichments/
Kafka properties are passed to the enricher via a config file:
enrich.hocon
enrich {
streams {
in {
raw = snowplow-good
}
out {
enriched = snowplow-enriched-good
bad = snowplow-enriched-bad
pii = snowplow-pii
partitionKey = user_ipaddress
}
sourceSink {
enabled = kafka
initialPosition = TRIM_HORIZON
brokers = "pkc-lzvrd.us-west4.gcp.confluent.cloud:9092"
retries = 0
producerConf {
acks = all
"security.protocol" = "SASL_SSL"
"sasl.jaas.config" = "org.apache.kafka.common.security.plain.PlainLoginModule required username='FQJBR6FKE5PQCAKH' password='********';"
"sasl.mechanism" = "PLAIN"
"client.dns.lookup" = "use_all_dns_ips"
}
consumerConf {
"security.protocol" = "SASL_SSL"
"sasl.jaas.config" = "org.apache.kafka.common.security.plain.PlainLoginModule required username='FQJBR6FKE5PQCAKH' password='********';"
"sasl.mechanism" = "PLAIN"
"client.dns.lookup" = "use_all_dns_ips"
"enable.auto.commit" = true
"auto.commit.interval.ms" = 1000
"auto.offset.reset" = earliest
"session.timeout.ms" = 30000
"key.deserializer" = "org.apache.kafka.common.serialization.StringDeserializer"
"value.deserializer" = "org.apache.kafka.common.serialization.ByteArrayDeserializer"
}
}
buffer {
byteLimit = 16384
recordLimit = 5
timeLimit = 1000
}
appName = "snowplow-enrich"
}
}
We added enrichments to parse the user-agent and perform a geoIP lookup (i.e. add the location, based on the IP address) by adding JSON files to the enrichments folder:
ip_lookups.json
{
"schema":"iglu:com.snowplowanalytics.snowplow/ip_lookups/jsonschema/2-0-0",
"data":{
"name":"ip_lookups",
"vendor":"com.snowplowanalytics.snowplow",
"enabled":true,
"parameters":{
"geo":{
"database":"GeoIP2-City.mmdb",
"uri":"https://woolford-maxmind.s3.amazonaws.com"
}
}
}
}
yauaa_enrichment_config.json
{
"schema":"iglu:com.snowplowanalytics.snowplow.enrichments/yauaa_enrichment_config/jsonschema/1-0-0",
"data":{
"enabled":true,
"vendor":"com.snowplowanalytics.snowplow.enrichments",
"name":"yauaa_enrichment_config"
}
}
JSON events
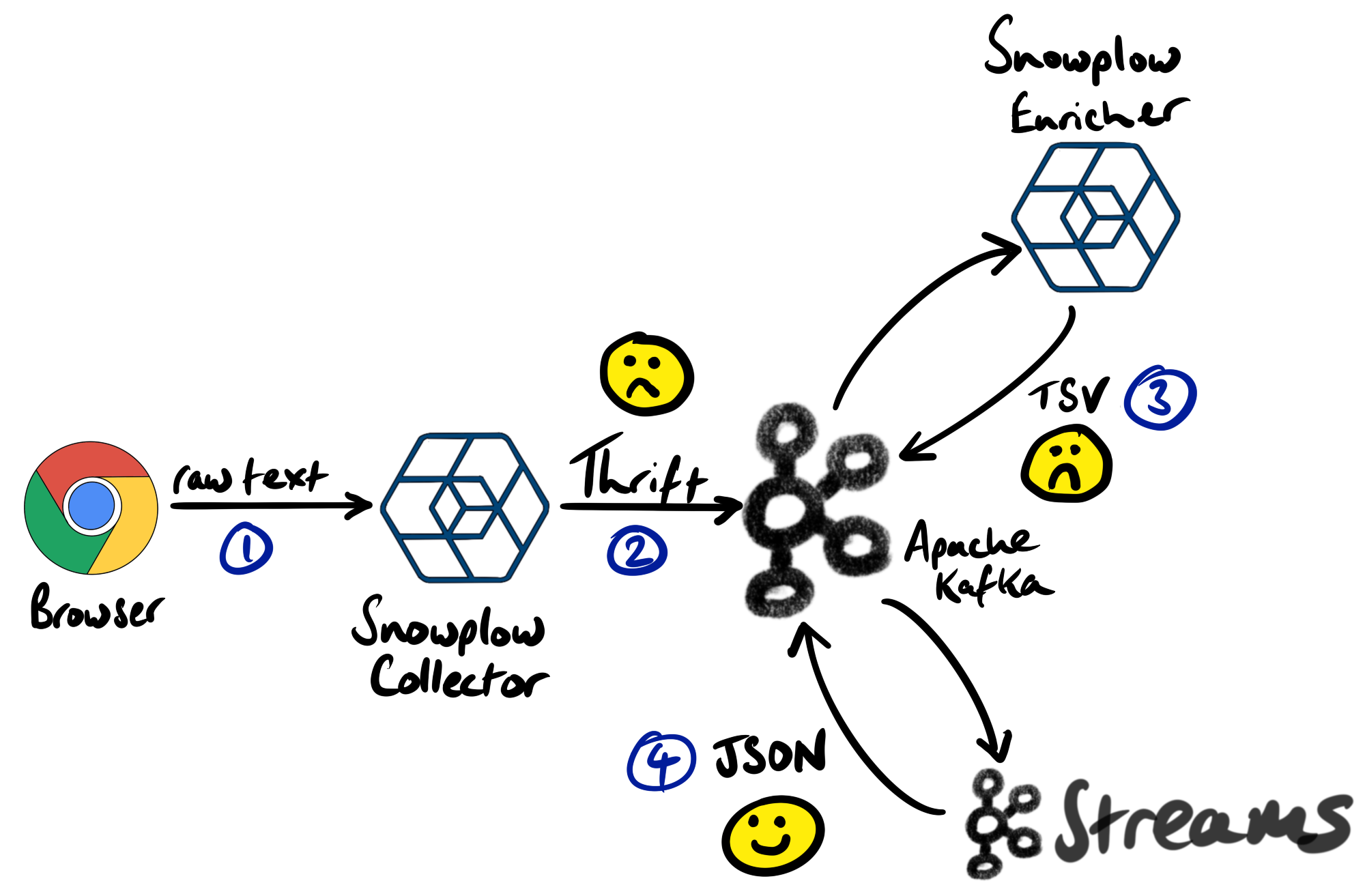
JSON is arguably the easiest and most common serialization format for technology integration. Unfortunately, JSON isn’t a format that’s used by Snowplow. The Collector serializes messages using Apache Thrift, and the Enricher converts those messages to tab-separated variable (tsv) format.
For ease-of-integration, we wrote a Kafka Streams job that takes the TSV formatted, enriched events and converts them to JSON. The job was embedded in a Docker container so it’s easy to deploy.
docker run -d --env-file snowplow-ccloud.env alexwoolford/snowplow-kafka-streams:latest
snowplow-ccloud.env
SNOWPLOW_KAFKA_BOOTSTRAP_SERVERS=pkc-lzvrd.us-west4.gcp.confluent.cloud:9092
SNOWPLOW_KAFKA_SECURITY_PROTOCOL=SASL_SSL
SNOWPLOW_KAFKA_SASL_JAAS_CONFIG=org.apache.kafka.common.security.plain.PlainLoginModule required username='FQJBR6FKE5PQCAKH' password='********';
SNOWPLOW_KAFKA_SASL_MECHANISM=PLAIN
Here’s a sample pageview event from Kafka:
{
"app_id":"woolford.io",
"platform":"web",
"etl_tstamp":"2021-08-06T23:46:48.441Z",
"collector_tstamp":"2021-08-06T23:46:46.818Z",
"dvce_created_tstamp":"2021-08-06T23:46:45.894Z",
"event":"page_view",
"event_id":"a1e6bed9-92a4-47bc-bfa7-8cfc92211c95",
"name_tracker":"cf",
"v_tracker":"js-3.1.0",
"v_collector":"ssc-2.3.0-kafka",
"v_etl":"stream-2.0.1-common-2.0.1",
"user_ipaddress":"172.58.140.122",
"domain_userid":"47aeb6c3-ce09-48d6-a66d-d4223669dc39",
"domain_sessionidx":44,
"network_userid":"32ba67c7-75d5-4cae-9e2d-1122e0a2ab2d",
"geo_country":"US",
"geo_region":"IL",
"geo_city":"Chicago",
"geo_zipcode":"60630",
"geo_latitude":41.9699,
"geo_longitude":-87.7603,
"geo_region_name":"Illinois",
"page_url":"https://woolford.io/2021-07-19-capture-snowplow-events-in-ccloud/",
"page_title":"capture Snowplow events in Kafka",
"page_referrer":"https://woolford.io/",
"page_urlscheme":"https",
"page_urlhost":"woolford.io",
"page_urlport":443,
"page_urlpath":"/2021-07-19-capture-snowplow-events-in-ccloud/",
"refr_urlscheme":"https",
"refr_urlhost":"woolford.io",
"refr_urlport":443,
"refr_urlpath":"/",
"contexts":{
"schema":"iglu:com.snowplowanalytics.snowplow/contexts/jsonschema/1-0-0",
"data":[
{
"schema":"iglu:com.snowplowanalytics.snowplow/web_page/jsonschema/1-0-0",
"data":{
"id":"1525050e-23ba-4b81-9fed-b0b176db740e"
}
}
]
},
"useragent":"Mozilla/5.0 (Linux; Android 11; Pixel 4a (5G)) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Mobile Safari/537.36",
"br_lang":"en-US",
"br_cookies":true,
"br_colordepth":"24",
"br_viewwidth":412,
"br_viewheight":717,
"os_timezone":"America/Denver",
"dvce_screenwidth":412,
"dvce_screenheight":892,
"doc_charset":"UTF-8",
"doc_width":412,
"doc_height":5758,
"geo_timezone":"America/Chicago",
"dvce_sent_tstamp":"2021-08-06T23:46:45.901Z",
"derived_contexts":{
"schema":"iglu:com.snowplowanalytics.snowplow/contexts/jsonschema/1-0-0",
"data":[
{
"schema":"iglu:nl.basjes/yauaa_context/jsonschema/1-0-2",
"data":{
"deviceBrand":"Google",
"deviceName":"Google Pixel 4A (5G)",
"operatingSystemVersionMajor":"11",
"layoutEngineNameVersion":"Blink 92.0",
"operatingSystemNameVersion":"Android 11",
"layoutEngineNameVersionMajor":"Blink 92",
"operatingSystemName":"Android",
"agentVersionMajor":"92",
"layoutEngineVersionMajor":"92",
"deviceClass":"Phone",
"agentNameVersionMajor":"Chrome 92",
"operatingSystemNameVersionMajor":"Android 11",
"operatingSystemClass":"Mobile",
"layoutEngineName":"Blink",
"agentName":"Chrome",
"agentVersion":"92.0.4515.131",
"layoutEngineClass":"Browser",
"agentNameVersion":"Chrome 92.0.4515.131",
"operatingSystemVersion":"11",
"agentClass":"Browser",
"layoutEngineVersion":"92.0"
}
}
]
},
"domain_sessionid":"d6452a8f-b7c0-4613-b225-f359ae10d931",
"derived_tstamp":"2021-08-06T23:46:46.811Z",
"event_vendor":"com.snowplowanalytics.snowplow",
"event_name":"page_view",
"event_format":"jsonschema",
"event_version":"1-0-0"
}
You can see that it contains a wealth of detailed information about the user. The domain_userid is an ID generated by the Snowplow Javascript tag that’s stored in a cookie. That’s the field we’ll use to identify the user.
“If I could turn back time” - Cher
Kafka’s ability to replay messages gives us a lot of freedom to experiment and iterate. The default retention policy for a Kafka topic is one week. We enabled infinite retention on the raw topic:

Perhaps we decide, in a years time, that we now have a use-case for Facebook cookies. We can add a cookie extractor enrichment, re-play the data, and then add those new data artifacts to the recommender graph or any other downstream process.
next…
Now that we have these JSON-serialized events in Kafka, we can build a real-time graph-based recommendations engine using Neo4j. That will be the topic of a follow-up post.